
Technology
Google Gemini: everything you need to know about the new generative artificial intelligence platform

Google is trying to impress with Gemini, its flagship suite of generative AI models, applications and services.
So what are Gemini? How can you use it? And how does it compare to the competition?
To help you sustain with the latest Gemini developments, we have created this handy guide, which we’ll keep updating as new Gemini models, features, and news about Google’s plans for Gemini grow to be available.
What is Gemini?
Gemini is owned by Google long promised, a family of next-generation GenAI models developed by Google’s artificial intelligence labs DeepMind and Google Research. It is available in three flavors:
- Gemini Ultrathe best Gemini model.
- Gemini Pro“lite” Gemini model.
- Gemini Nanoa smaller “distilled” model that works on mobile devices like the Pixel 8 Pro.
All Gemini models were trained to be “natively multimodal” – in other words, able to work with and use greater than just words. They were pre-trained and tuned based on various audio files, images and videos, a big set of codebases and text in various languages.
This distinguishes Gemini from models akin to Google’s LaMDA, which was trained solely on text data. LaMDA cannot understand or generate anything beyond text (e.g. essays, email drafts), but this isn’t the case with Gemini models.
What is the difference between Gemini Apps and Gemini Models?
Image credits: Google
Google, proving once more that it has no talent for branding, didn’t make it clear from the starting that Gemini was separate and distinct from the Gemini web and mobile app (formerly Bard). Gemini Apps is solely an interface through which you can access certain Gemini models – consider it like Google’s GenAI client.
Incidentally, Gemini applications and models are also completely independent of Imagen 2, Google’s text-to-image model available in a few of the company’s development tools and environments.
What can Gemini do?
Because Gemini models are multimodal, they will theoretically perform a spread of multimodal tasks, from transcribing speech to adding captions to images and videos to creating graphics. Some of those features have already reached the product stage (more on that later), and Google guarantees that each one of them – and more – can be available in the near future.
Of course, it is a bit difficult to take the company’s word for it.
Google seriously fell in need of expectations when it got here to the original Bard launch. Recently, it caused a stir by publishing a video purporting to show the capabilities of Gemini, which turned out to be highly fabricated and kind of aspirational.
Still, assuming Google is kind of honest in its claims, here’s what the various tiers of Gemini will give you the option to do once they reach their full potential:
Gemini Ultra
Google claims that Gemini Ultra – thanks to its multimodality – may help with physics homework, solve step-by-step problems in a worksheet and indicate possible errors in already accomplished answers.
Gemini Ultra can be used for tasks akin to identifying scientific articles relevant to a selected problem, Google says, extracting information from those articles and “updating” a graph from one by generating the formulas needed to recreate the graph with newer data.
Gemini Ultra technically supports image generation as mentioned earlier. However, this feature has not yet been implemented in the finished model – perhaps because the mechanism is more complex than the way applications akin to ChatGPT generate images. Instead of passing hints to a picture generator (akin to DALL-E 3 for ChatGPT), Gemini generates images “natively” with no intermediate step.
Gemini Ultra is accessible as an API through Vertex AI, Google’s fully managed platform for AI developers, and AI Studio, Google’s online tool for application and platform developers. It also supports Gemini apps – but not totally free. Access to Gemini Ultra through what Google calls Gemini Advanced requires a subscription to the Google One AI premium plan, which is priced at $20 monthly.
The AI Premium plan also connects Gemini to your broader Google Workspace account—think emails in Gmail, documents in Docs, presentations in Sheets, and Google Meet recordings. This is useful, for instance, when Gemini is summarizing emails or taking notes during a video call.
Gemini Pro
Google claims that Gemini Pro is an improvement over LaMDA by way of inference, planning and understanding capabilities.
Independent test by Carnegie Mellon and BerriAI researchers found that the initial version of Gemini Pro was actually higher than OpenAI’s GPT-3.5 at handling longer and more complex reasoning chains. However, the study also found that, like all major language models, this version of Gemini Pro particularly struggled with math problems involving several digits, and users found examples of faulty reasoning and obvious errors.
However, Google promised countermeasures – and the first one got here in the type of Gemini 1.5 Pro.
Designed as a drop-in substitute, Gemini 1.5 Pro has been improved in lots of areas compared to its predecessor, perhaps most notably in the amount of information it could actually process. Gemini 1.5 Pro can write ~700,000 words or ~30,000 lines of code – 35 times greater than Gemini 1.0 Pro. Moreover – the model is multimodal – it isn’t limited to text. Gemini 1.5 Pro can analyze up to 11 hours of audio or an hour of video in various languages, albeit at a slow pace (e.g., looking for a scene in an hour-long movie takes 30 seconds to a minute).
Gemini 1.5 Pro entered public preview on Vertex AI in April.
An additional endpoint, Gemini Pro Vision, can process text images – including photos and videos – and display text according to the GPT-4 model with Vision OpenAI.
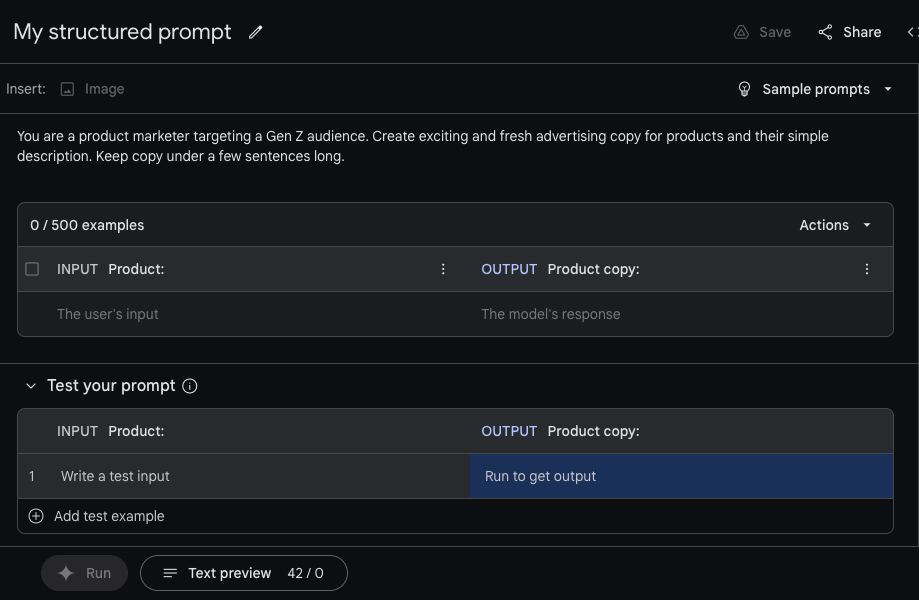
Using Gemini Pro with Vertex AI. Image credits: Twins
Within Vertex AI, developers can tailor Gemini Pro to specific contexts and use cases through a tuning or “grounding” process. Gemini Pro can be connected to external third-party APIs to perform specific actions.
AI Studio includes workflows for creating structured chat prompts using Gemini Pro. Developers have access to each Gemini Pro and Gemini Pro Vision endpoints and might adjust model temperature to control creative scope and supply examples with tone and elegance instructions, in addition to fine-tune security settings.
Gemini Nano
The Gemini Nano is a much smaller version of the Gemini Pro and Ultra models, and is powerful enough to run directly on (some) phones, slightly than sending the job to a server somewhere. So far, it supports several features on the Pixel 8 Pro, Pixel 8, and Samsung Galaxy S24, including Summarize in Recorder and Smart Reply in Gboard.
The Recorder app, which allows users to record and transcribe audio with the touch of a button, provides a Gemini-powered summary of recorded conversations, interviews, presentations and more. Users receive these summaries even in the event that they do not have a signal or Wi-Fi connection available – and in a nod to privacy, no data leaves their phone.
Gemini Nano can be available on Gboard, Google’s keyboard app. There, it supports a feature called Smart Reply that helps you suggest the next thing you’ll want to say while chatting in the messaging app. The feature initially only works with WhatsApp, but can be available in additional apps over time, Google says.
In the Google News app on supported devices, the Nano enables Magic Compose, which allows you to compose messages in styles akin to “excited”, “formal”, and “lyrical”.
Is Gemini higher than OpenAI’s GPT-4?
Google has had this occur a number of times advertised Gemini’s benchmarking superiority, claiming that Gemini Ultra outperforms current state-of-the-art results on “30 of 32 commonly used academic benchmarks used in the research and development of large language models.” Meanwhile, the company claims that Gemini 1.5 Pro is best able to perform tasks akin to summarizing content, brainstorming, and writing higher than Gemini Ultra in some situations; it will probably change with the premiere of the next Ultra model.
However, leaving aside the query of whether the benchmarks actually indicate a greater model, the results that Google indicates appear to be only barely higher than the corresponding OpenAI models. And – as mentioned earlier – some initial impressions weren’t great, each amongst users and others scientists mentioning that the older version of Gemini Pro tends to misinterpret basic facts, has translation issues, and provides poor coding suggestions.
How much does Gemini cost?
Gemini 1.5 Pro is free to use in Gemini apps and, for now, in AI Studio and Vertex AI.
However, when Gemini 1.5 Pro leaves the preview in Vertex, the model will cost $0.0025 per character, while the output will cost $0.00005 per character. Vertex customers pay per 1,000 characters (roughly 140 to 250 words) and, for models like the Gemini Pro Vision, per image ($0.0025).
Let’s assume a 500-word article incorporates 2,000 characters. To summarize this text with the Gemini 1.5 Pro will cost $5. Meanwhile, generating an article of comparable length will cost $0.1.
Pricing for the Ultra has not yet been announced.
Where can you try Gemini?
Gemini Pro
The easiest place to use Gemini Pro is in the Gemini apps. Pro and Ultra respond to queries in multiple languages.
Gemini Pro and Ultra are also available in preview on Vertex AI via API. The API is currently free to use “within limits” and supports certain regions including Europe, in addition to features akin to chat and filtering.
Elsewhere, Gemini Pro and Ultra might be present in AI Studio. Using this service, developers can iterate on Gemini-based prompts and chatbots after which obtain API keys to use them of their applications or export the code to a more complete IDE.
Code Assistant (formerly AI duo for programmers), Google’s suite of AI-based code completion and generation tools uses Gemini models. Developers could make “large-scale” changes to code bases, akin to updating file dependencies and reviewing large snippets of code.
Google has introduced Gemini models in its development tools for the Chrome and Firebase mobile development platform and database creation and management tools. It has also introduced new security products based on Gemini technology, e.g Gemini in Threat Intelligence, a component of Google’s Mandiant cybersecurity platform that may analyze large chunks of probably malicious code and enable users to search in natural language for persistent threats or indicators of compromise.












Elon Musk says his duty is to “make new people.” Now Investigation of WSJ He suggests that he could start greater than 14 known children, and the sources claim that the actual number will be much higher. The report also describes how Musk keeps these details within the package.
In the middle of all this, based on the report, there may be a longtime Fixer Jared Birchall, which runs the Muska’s family office, but additionally supports the logistics of the developing Muska family, including by developing Hush contracts and serving as a board for moms of some children.
For example, Musk reportedly asked the conservative influence of Ashley St. Clair for signing a restrictive agreement after she gave birth to their son last autumn. Agreement: $ 15 million plus an extra $ 100,000 per 30 days, so long as the kid is 21 in exchange for her silence. She refused; He says that the contract worsens with every treason perceived. (She told the journal that the Muska team sent her only $ 20,000 after they bowed to Musk to comment on his article).
As for Birchall, which can also be CEO Press-IMPLANTU-IMPLANTU VENTURE NEURALK IA partner In AI Venture XAI in Musk, Muska’s private life management can simply be the third full -time job. According to the journal, in a single two -hour conversation with St. Clair, Birchall told her that the transition “legal path” with musk “always, always leads to a worse result for this woman than otherwise.”

The joint company Micromobility Lime has reached an agreement on sending batteries utilized in scooters and electronic bikes to Sewoi materials that extract and recycle critical minerals, comparable to lithium, cobalt, nickel and copper.
The agreement announced on Monday makes Redwood Materials the only real battery recycling partner for common scooters and e-bike bikes situated in cities within the United States, Germany and the Netherlands. The contract doesn’t cover every region where lime worksAn inventory covering cities throughout Europe, Asia and Australia.
In Lime up to now he had other recycling partnerships, especially with Sprout through his suppliers. However, for the primary time, the joint company Micromobility had direct relations with battery recycling in North America, which might directly process the fabric for recovery and returns it to the availability chain.
Redwood Materials, The Carson City, Startup from Nevada founded by the previous CFO Tesla JB Straubel, will get better battery materials when they can’t be used. After recovering and recycling, the materials will be re -introduced within the battery production process. This production system of a closed loop-which can reduce the demand for extraction and refining of minerals-is on the Redwood Materials business center.
The effort can also be consistent with its own goals of limestone sustainable development. Lime is geared toward decarbonization of operations by 2030. The company has made progress in reducing the range 1, 2 and 3 of emissions by 59.5% in five years of basic years 2019. Wapno plans to report the outcomes of carbon dioxide emissions 2024 in May.
“This cooperation means significant progress in the establishment of a more round supply chain, helping our batteries not only to recycled responsibly after reaching the end of their lives, but that their materials are returned to the battery supply chain,” said Andrew Savage, vice chairman for balanced development in Lime.
Lime also has partnerships from Gomi in Great Britain and Voltr in France and other European countries to gather these live battery cells for “Second Life” applications, including, amongst others, in the sphere of consumer electronics, comparable to portable speakers and battery packages.
Redwood Materials has contracts with other micromobility corporations, including Lyft, RAD Power Bikes and bicycle batteries and scooters specialized in recycling. Redwood, which collected over $ 2 billion in private funds, announced at first of this month, opened the research and development center in San Francisco.
(Tagstranslat) ebikes

On April 11, the Legal Defense Fund announced that he was leaving the external advisory council for civil rights regarding the fear that the changes in technology company introduced diversity, own capital, inclusion and availability in January.
According to those changes that some perceived as the capitulation of meta against the upcoming Trump administration, contributed to their decision To leave the advisory council of the technology company.
In January, LDF, along with several other organizations of civil rights, which were a part of the board, sent a letter to Marek Zuckerberg, CEO of Meta, outlining their fears As for a way changes would negatively affect users.
“We are shocked and disappointed that the finish has not consulted with this group or its members, considering these significant changes in its content policy. Non -compliance with even its own advisory group of experts on external civil rights shows a cynical disregard for its diverse users base and undermines the commitment of the meta in the field of freedom of speech with which he claims to” return “.
They closed the letter, hoping that the finish would recommend the ideals of freedom of speech: “If the finish really wants to recommend freedom of speech, he must commit to freedom of speech for all his services. As an advisory group from external civil rights, we offer our advice and knowledge in creating a better path.”
These fears increased only in the next months, culminating in one other list, which from the LDF director, Todd A. Cox, who indicated that the organization withdraws its membership from the META civil law advisory council.
“I am deeply disturbed and disappointed with the announcement of Medical on January 7, 2025, with irresponsible changes in content moderation policies on platforms, which are a serious risk for the health and safety of black communities and risk that they destabilize our republic,” Cox wrote.
He continued: “For almost a decade, the NACP Legal Defense and Educational Fund, Inc. (LDF) has invested a lot of time and resources, working with META as part of the informal committee advising the company in matters of civil rights. However, the finish introduced these changes in the policy of the content modification without consulting this group, and many changes directly with the guidelines from the guidelines from LDF and partners. LD can no longer participate in the scope. ” Advisory Committee for Rights “
In a separate but related LDF list, it clearly resembled a finish about the actual obligations of the Citizens’ Rights Act of 1964 and other provisions regarding discrimination in the workplace, versus the false statements of the Trump administration, that diversity, justice and initiative to incorporate discriminates against white Americans.
“While the finish has modified its policy, its obligations arising from federal regulations regarding civil rights remain unchanged. The title of VII of the Act on civic rights of 1964 and other regulations on civil rights prohibit discrimination in the workplace, including disconnecting treatment, principles in the workplace which have unfair disproportionate effects, and the hostile work environment. Also when it comes to inclusion, and access programs.
In the LDF press release, announcing each letters, Cox He called attention Metal insert into growing violence and division in the country’s social climate.
“LDF worked hard and in good faith with meta leadership and its consulting group for civil rights to ensure that the company’s workforce reflects the values and racial warehouses of the United States and to increase the security priorities of many different communities that use meta platforms,” said Cox. “Now we cannot support a company in good conscience that consciously takes steps in order to introduce changes in politics that supply further division and violence in the United States. We call the meta to reverse the course with these dangerous changes.”
(Tagstranslate) TODD A. COX (T) Legal Defense Fund (T) META (T) Diversity (T) Equality (T) inclusion


Chinedu Echeruo Founder of HopStop.com

Fans of “Pop The Balloon” say that Netflix ruined the series with a gentrification – can they still fix it?
As Musk manages his growing family: WSJ

The prosecutor says that Sean “Diddy” Combs “lawyers are looking for reasons to delay his May trial

17-year-old accused in Texas




-

 Press Release1 year ago
Press Release1 year agoU.S.-Africa Chamber of Commerce Appoints Robert Alexander of 360WiseMedia as Board Director
-

 Press Release1 year ago
Press Release1 year agoCEO of 360WiSE Launches Mentorship Program in Overtown Miami FL
-

 Business and Finance11 months ago
Business and Finance11 months agoThe Importance of Owning Your Distribution Media Platform
-

 Business and Finance1 year ago
Business and Finance1 year ago360Wise Media and McDonald’s NY Tri-State Owner Operators Celebrate Success of “Faces of Black History” Campaign with Over 2 Million Event Visits
-

 Ben Crump1 year ago
Ben Crump1 year agoAnother lawsuit accuses Google of bias against Black minority employees
-

 Theater1 year ago
Theater1 year agoTelling the story of the Apollo Theater
-

 Ben Crump1 year ago
Ben Crump1 year agoHenrietta Lacks’ family members reach an agreement after her cells undergo advanced medical tests
-

 Ben Crump1 year ago
Ben Crump1 year agoThe families of George Floyd and Daunte Wright hold an emotional press conference in Minneapolis
-

 Theater1 year ago
Theater1 year agoApplications open for the 2020-2021 Soul Producing National Black Theater residency – Black Theater Matters
-

 Theater11 months ago
Theater11 months agoCultural icon Apollo Theater sets new goals on the occasion of its 85th anniversary