Technology
Google Gemini: everything you need to know about the new generative artificial intelligence platform


Google is trying to impress with Gemini, its flagship suite of generative AI models, applications and services.
So what are Gemini? How can you use it? And how does it compare to the competition?
To help you sustain with the latest Gemini developments, we have created this handy guide, which we’ll keep updating as new Gemini models, features, and news about Google’s plans for Gemini grow to be available.
What is Gemini?
Gemini is owned by Google long promised, a family of next-generation GenAI models developed by Google’s artificial intelligence labs DeepMind and Google Research. It is available in three flavors:
- Gemini Ultrathe best Gemini model.
- Gemini Pro“lite” Gemini model.
- Gemini Nanoa smaller “distilled” model that works on mobile devices like the Pixel 8 Pro.
All Gemini models were trained to be “natively multimodal” – in other words, able to work with and use greater than just words. They were pre-trained and tuned based on various audio files, images and videos, a big set of codebases and text in various languages.
This distinguishes Gemini from models akin to Google’s LaMDA, which was trained solely on text data. LaMDA cannot understand or generate anything beyond text (e.g. essays, email drafts), but this isn’t the case with Gemini models.
What is the difference between Gemini Apps and Gemini Models?
Image credits: Google
Google, proving once more that it has no talent for branding, didn’t make it clear from the starting that Gemini was separate and distinct from the Gemini web and mobile app (formerly Bard). Gemini Apps is solely an interface through which you can access certain Gemini models – consider it like Google’s GenAI client.
Incidentally, Gemini applications and models are also completely independent of Imagen 2, Google’s text-to-image model available in a few of the company’s development tools and environments.
What can Gemini do?
Because Gemini models are multimodal, they will theoretically perform a spread of multimodal tasks, from transcribing speech to adding captions to images and videos to creating graphics. Some of those features have already reached the product stage (more on that later), and Google guarantees that each one of them – and more – can be available in the near future.
Of course, it is a bit difficult to take the company’s word for it.
Google seriously fell in need of expectations when it got here to the original Bard launch. Recently, it caused a stir by publishing a video purporting to show the capabilities of Gemini, which turned out to be highly fabricated and kind of aspirational.
Still, assuming Google is kind of honest in its claims, here’s what the various tiers of Gemini will give you the option to do once they reach their full potential:
Gemini Ultra
Google claims that Gemini Ultra – thanks to its multimodality – may help with physics homework, solve step-by-step problems in a worksheet and indicate possible errors in already accomplished answers.
Gemini Ultra can be used for tasks akin to identifying scientific articles relevant to a selected problem, Google says, extracting information from those articles and “updating” a graph from one by generating the formulas needed to recreate the graph with newer data.
Gemini Ultra technically supports image generation as mentioned earlier. However, this feature has not yet been implemented in the finished model – perhaps because the mechanism is more complex than the way applications akin to ChatGPT generate images. Instead of passing hints to a picture generator (akin to DALL-E 3 for ChatGPT), Gemini generates images “natively” with no intermediate step.
Gemini Ultra is accessible as an API through Vertex AI, Google’s fully managed platform for AI developers, and AI Studio, Google’s online tool for application and platform developers. It also supports Gemini apps – but not totally free. Access to Gemini Ultra through what Google calls Gemini Advanced requires a subscription to the Google One AI premium plan, which is priced at $20 monthly.
The AI Premium plan also connects Gemini to your broader Google Workspace account—think emails in Gmail, documents in Docs, presentations in Sheets, and Google Meet recordings. This is useful, for instance, when Gemini is summarizing emails or taking notes during a video call.
Gemini Pro
Google claims that Gemini Pro is an improvement over LaMDA by way of inference, planning and understanding capabilities.
Independent test by Carnegie Mellon and BerriAI researchers found that the initial version of Gemini Pro was actually higher than OpenAI’s GPT-3.5 at handling longer and more complex reasoning chains. However, the study also found that, like all major language models, this version of Gemini Pro particularly struggled with math problems involving several digits, and users found examples of faulty reasoning and obvious errors.
However, Google promised countermeasures – and the first one got here in the type of Gemini 1.5 Pro.
Designed as a drop-in substitute, Gemini 1.5 Pro has been improved in lots of areas compared to its predecessor, perhaps most notably in the amount of information it could actually process. Gemini 1.5 Pro can write ~700,000 words or ~30,000 lines of code – 35 times greater than Gemini 1.0 Pro. Moreover – the model is multimodal – it isn’t limited to text. Gemini 1.5 Pro can analyze up to 11 hours of audio or an hour of video in various languages, albeit at a slow pace (e.g., looking for a scene in an hour-long movie takes 30 seconds to a minute).
Gemini 1.5 Pro entered public preview on Vertex AI in April.
An additional endpoint, Gemini Pro Vision, can process text images – including photos and videos – and display text according to the GPT-4 model with Vision OpenAI.

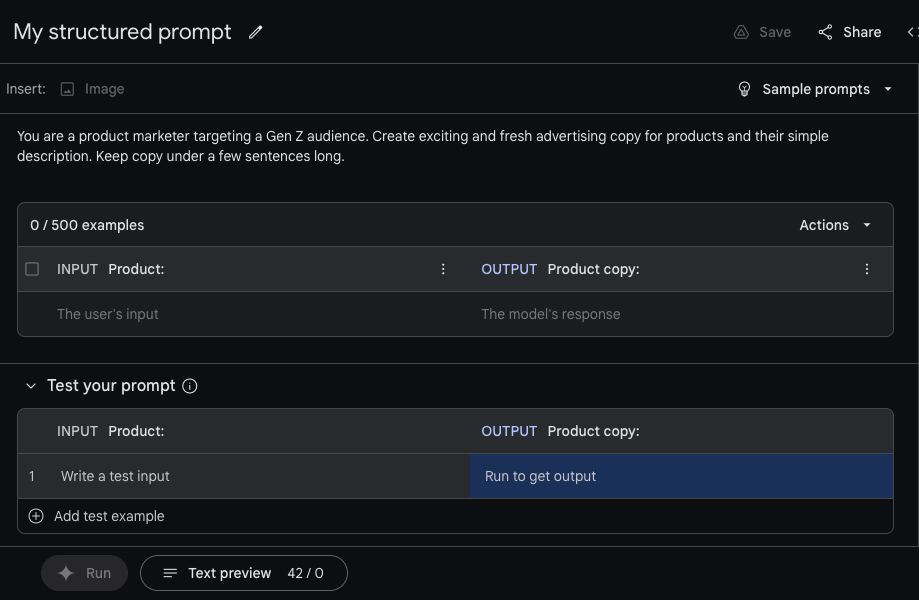
Using Gemini Pro with Vertex AI. Image credits: Twins
Within Vertex AI, developers can tailor Gemini Pro to specific contexts and use cases through a tuning or “grounding” process. Gemini Pro can be connected to external third-party APIs to perform specific actions.
AI Studio includes workflows for creating structured chat prompts using Gemini Pro. Developers have access to each Gemini Pro and Gemini Pro Vision endpoints and might adjust model temperature to control creative scope and supply examples with tone and elegance instructions, in addition to fine-tune security settings.
Gemini Nano
The Gemini Nano is a much smaller version of the Gemini Pro and Ultra models, and is powerful enough to run directly on (some) phones, slightly than sending the job to a server somewhere. So far, it supports several features on the Pixel 8 Pro, Pixel 8, and Samsung Galaxy S24, including Summarize in Recorder and Smart Reply in Gboard.
The Recorder app, which allows users to record and transcribe audio with the touch of a button, provides a Gemini-powered summary of recorded conversations, interviews, presentations and more. Users receive these summaries even in the event that they do not have a signal or Wi-Fi connection available – and in a nod to privacy, no data leaves their phone.
Gemini Nano can be available on Gboard, Google’s keyboard app. There, it supports a feature called Smart Reply that helps you suggest the next thing you’ll want to say while chatting in the messaging app. The feature initially only works with WhatsApp, but can be available in additional apps over time, Google says.
In the Google News app on supported devices, the Nano enables Magic Compose, which allows you to compose messages in styles akin to “excited”, “formal”, and “lyrical”.
Is Gemini higher than OpenAI’s GPT-4?
Google has had this occur a number of times advertised Gemini’s benchmarking superiority, claiming that Gemini Ultra outperforms current state-of-the-art results on “30 of 32 commonly used academic benchmarks used in the research and development of large language models.” Meanwhile, the company claims that Gemini 1.5 Pro is best able to perform tasks akin to summarizing content, brainstorming, and writing higher than Gemini Ultra in some situations; it will probably change with the premiere of the next Ultra model.
However, leaving aside the query of whether the benchmarks actually indicate a greater model, the results that Google indicates appear to be only barely higher than the corresponding OpenAI models. And – as mentioned earlier – some initial impressions weren’t great, each amongst users and others scientists mentioning that the older version of Gemini Pro tends to misinterpret basic facts, has translation issues, and provides poor coding suggestions.
How much does Gemini cost?
Gemini 1.5 Pro is free to use in Gemini apps and, for now, in AI Studio and Vertex AI.
However, when Gemini 1.5 Pro leaves the preview in Vertex, the model will cost $0.0025 per character, while the output will cost $0.00005 per character. Vertex customers pay per 1,000 characters (roughly 140 to 250 words) and, for models like the Gemini Pro Vision, per image ($0.0025).
Let’s assume a 500-word article incorporates 2,000 characters. To summarize this text with the Gemini 1.5 Pro will cost $5. Meanwhile, generating an article of comparable length will cost $0.1.
Pricing for the Ultra has not yet been announced.
Where can you try Gemini?
Gemini Pro
The easiest place to use Gemini Pro is in the Gemini apps. Pro and Ultra respond to queries in multiple languages.
Gemini Pro and Ultra are also available in preview on Vertex AI via API. The API is currently free to use “within limits” and supports certain regions including Europe, in addition to features akin to chat and filtering.
Elsewhere, Gemini Pro and Ultra might be present in AI Studio. Using this service, developers can iterate on Gemini-based prompts and chatbots after which obtain API keys to use them of their applications or export the code to a more complete IDE.
Code Assistant (formerly AI duo for programmers), Google’s suite of AI-based code completion and generation tools uses Gemini models. Developers could make “large-scale” changes to code bases, akin to updating file dependencies and reviewing large snippets of code.
Google has introduced Gemini models in its development tools for the Chrome and Firebase mobile development platform and database creation and management tools. It has also introduced new security products based on Gemini technology, e.g Gemini in Threat Intelligence, a component of Google’s Mandiant cybersecurity platform that may analyze large chunks of probably malicious code and enable users to search in natural language for persistent threats or indicators of compromise.